Er zijn specificaties van een vroege Lunar Lake-processor uitgelekt, waaronder het aantal cores, de hoeveelheid cache en de kloksnelheden. De informatie suggereert dat Lunar Lake geen hyperthreading ondersteunt. Lunar Lake is bedoeld voor laptops en komt eind dit jaar uit.
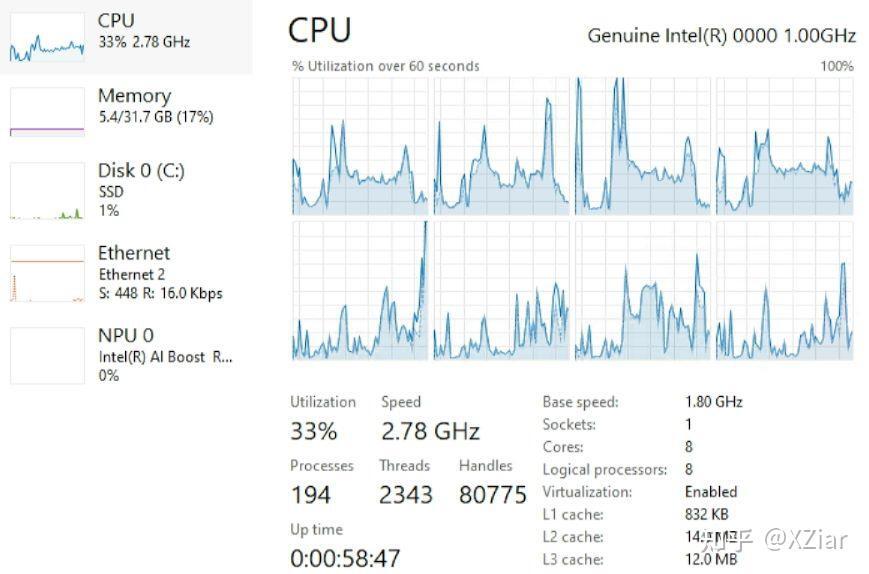
De Intel Lunar Lake-specificaties werden gepubliceerd door Zhihi-gebruiker XZiar, zo merkte @9550pro op. Die gebruiker publiceerde een screenshot van het Windows-taakbeheer met daarop specificaties van de komende cpu. Het betreft volgens XZiar een zogeheten A1-sample. Dergelijke chips zijn de eerste werkende prototypes die uit de chipfabriek komen. Dat betekent dat de chip niet het definitieve product betreft, hoewel de onderliggende architectuur vermoedelijk weinig gewijzigd zal worden voor de release later dit jaar.
De processor in kwestie beschikt over acht cores en acht threads. Daarmee zou hyperthreading dus niet meer ondersteund worden. Er gingen eerder al geruchten rond dat ook Intels komende Arrow Lake-platform, dat is bedoeld voor desktops, geen hyperthreading meer gaat ondersteunen. Volgens eerder uitgelekte informatie beschikt Lunar Lake over een combinatie van vier Lion Cove-P-cores en vier Skymont-E-cores.
Verder beschikt de processor in kwestie over 14MB L2-cache, verdeeld over 2,5MB per P-core en 4MB voor de vier E-kernen. De chip beschikt daarnaast over 12MB L3-cache. De kloksnelheid betreft in deze sample bijvoorbeeld 1,8GHz, met een boostclock van 2,8GHz. Aangezien het een vroege engineering sample betreft, zal dit waarschijnlijk worden opgehoogd in de releaseversie.
Intel kondigde de komst van Lunar Lake eerder al aan, hoewel het bedrijf nog geen concrete chips heeft aangekondigd. Het bedrijf toonde eerder een Lunar Lake-processor met geïntegreerd ram en bevestigde toen dat de chips later dit jaar uitkomen. Deze laptop-cpu’s komen beschikbaar naast de Arrow Lake-serie voor desktops, die ook dit jaar verschijnen.
De Lunar Lake-processors worden opgebouwd uit verschillende chiplets, net als de eerder verschenen Meteor Lake-serie. Volgens geruchten worden de cpu-cores voor deze processors geproduceerd bij TSMC op het N3B-procedé, hoewel Intel dat nog niet heeft bevestigd. Intel zei eerder dat Lunar Lake deels op zijn eigen 18A-node wordt geproduceerd, hoewel dat ook een ander deel van de cpu kan betreffen.

:strip_icc():strip_exif()/i/2006394226.jpeg?f=fpa_thumb)
/i/2006301718.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006169008.jpeg?f=fpa_thumb)
:strip_exif()/i/2006355622.jpeg?f=fpa)
:strip_exif()/i/2005990290.jpeg?f=fpa)
/i/2004611214.png?f=fpa)
:strip_exif()/i/2005682890.jpeg?f=fpa)
/i/2005537802.png?f=fpa)
:strip_exif()/i/2005833550.jpeg?f=fpa)